
前置知识与基本思路
Zhou 等人将软件供应链定义为“由于软件或软件项目之间互相依赖(如软件的构建或运行时依赖,开发者同时参与多个开源项目,软件代码的复制粘贴等)形成的复杂关系网” ,开源软件世界中软件制品和开发者间复杂而精妙的关系形成了开源软件供应链。
操作系统是关键基础软件,支撑着几乎所有领域的应用软件,是数字社会不可或缺的基础设施。如今以 Linux 为代表的开源操作系统发展迅猛,被应用到诸多关键领域。而开源操作系统的开发、维护、运行均依赖大量的开源软件包,软件包间错综复杂的依赖关系构成了操作系统软件供应链。
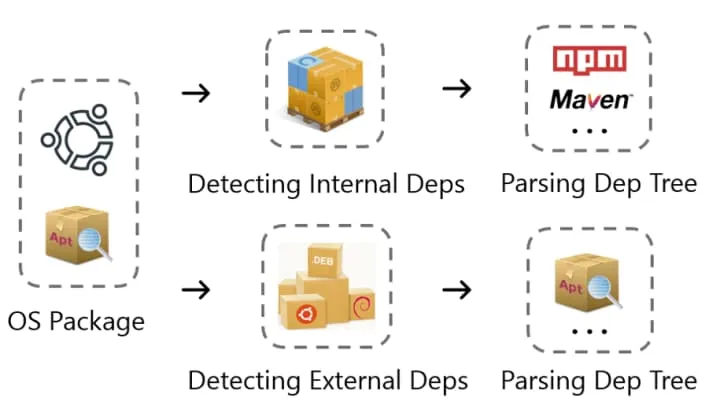
以构建整体的操作系统软件供应链为目标,首先需要实现一个合适的软件包依赖解析器,为供应链的构建提供数据基础。而如下图所示,在处理操作系统软件包间的依赖关系时,应当从两个方面入手分别完成依赖解析:
- 操作系统包管理器 - 外部依赖
- 应用层包管理器 - 内部依赖
解析操作系统软件包依赖关系
软件包数据预处理
Ubuntu 的包管理系统沿承自 Debian GNU/Linux,包文件中包含了实现在 Ubuntu 系统上特定功能或软件应用所需的所有文件、元数据和指令。依赖 (dependencies) 是软件包中的重要组成部分,它指的是主包 (principal package) 为了正常工作所需的额外包 (additional package)。
对于绝大多数的包而言,依赖是必不可少的,对于依赖项的管理也是 Ubuntu 的包管理机制中的关键一环。例如,语音合成包 festival 依赖于 alsa-utils 包,这是一个提供音频播放所续的 ALSA 声音库工具,而使用者为了正常运行 festival,必须安装它及其所有的依赖项。
在 Ubuntu 官方网站中,可以查阅到 22.04 版本的所有软件包。由于软件包数量庞杂,本文借助其提供的软件包列表的 txt.gz 压缩文件后续进行软件包名、版本号、类型的解析,有效数据共有十万余条,其基本格式如下:
All Ubuntu Packages in "jammy"
Generated: Sat May 13 03:36:47 2023 UTC
Copyright © 2023 Canonical Ltd.;
See <URL:http://www.ubuntu.com/legal> for the license terms.
0ad (0.0.25b-2) [universe] Real-time strategy game of ancient warfare
0ad-data (0.0.25b-1) [universe] Real-time strategy game of ancient warfare (data files)
... ...为实现软件包名和版本号的解析,以第一条有效数据 0ad (0.0.25b-2) 为例,软件包名为 0ad,版本号则以 Debian 软件包规定的形式呈现,具体规则为:[epoch:]upstream-version[-debian-revision]
- epoch:可选,用于覆盖先前的版本序列,个位的无符号整数,默认值为 0;
- upstream-version:版本号的主要部分,包含字母数字字符 (“A-Za-z0-9”) 和字符 “.+-:~”;
- debian-reversion:可选,指定了基于上游版本的 Debian 包的版本,包含字母数字字符和字符 “+.~”。
除此之外,虚包 (virtual package) 机制也是 Ubuntu 包管理系统中十分重要的一环。虚包是一个通用名称,适用于一组包中的任何一个,所有这些包都提供类似的基本功能。
对包列表进行简单的统计,虚包的数量约占所有软件包 33.9% (35079/103409),因此其存在对于依赖关系的解析是不可忽略的。在软件包列表中,虚包对应数据呈现格式为:
本文采用如下正则表达式进行解析,并对解析结果进行分组:
([0-9a-z\-\.\+]+)(?:\s\((.+?)\))* virtual package provided by (.+)?|
([0-9a-z\-\.\+]+)\s\((.+?)\)(?:\s\[(.+?)\]?)*\s(.+)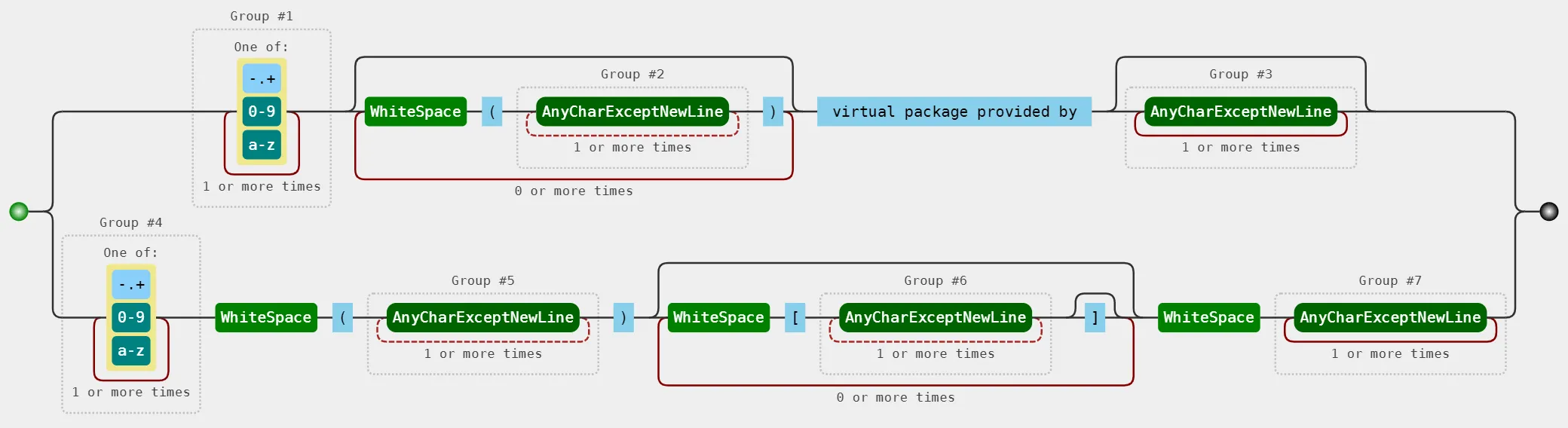
解析软件包间依赖关系
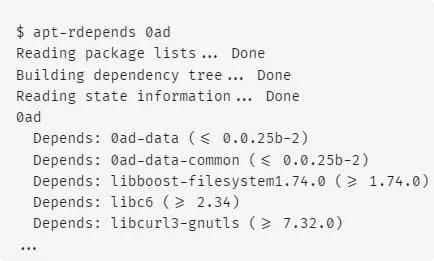
apt-rdepends 是一个在基于 Debian 的系统上使用的工具,它用于查询一个包的依赖关系。它可以同时解析软件包的正向依赖 (dependencies) 以及反向依赖(reverse dependencies)。这对于理解一个软件包的依赖性和它在系统中的位置非常有用。
apt show 同样也可用于显示特定软件包的信息。与前一种方案相比,其仅能给出软件包的正向依赖,而无法解析反向依赖,但 apt show 可以提供除依赖项之外的源包的更多的相关信息,如描述、版本、大小、维护者信息等。
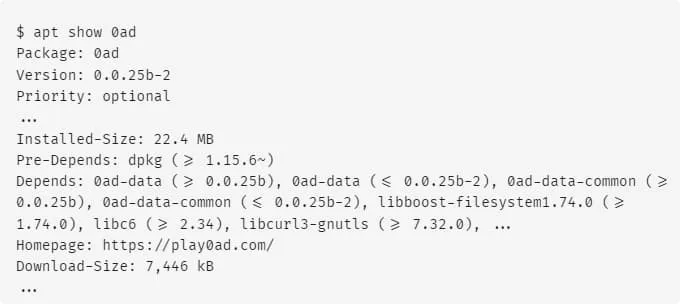
考差两者对于软件包 0ad 的解析结果的差异,可以对于发现依赖项中的第一项,即 0ad-data,apt-rdepends 仅给出一条版本约束条件 (),而 apt show 则给出两条版本约束条件 ()。通过查阅软件包相关信息,可以确定 apt show 给出的依赖项的版本约束是更正确的一方。因此,本文采用 apt show 顺次解析 Ubuntu 22.04 所有软件包的依赖项,将数据以<软件包名,软件包版本号>的形式进行存储,为进一步构建软件供应链提供数据源支撑。
解析应用层软件包依赖关系
为了从应用层入手,解析操作系统软件包的内部依赖,我们首先需要获取操作系统的所有软件包的源码。
apt-cache 命令可显示 apt 内部数据库里的多种信息,这些信息是于运行 apt update 指令时产生的从 sources.list 文件内聚集不同来源的缓存。而 apt-cache dumpavail 则是 apt-cache 命令的一个参数,用于显示所有软件包全部版本的标头,我们采用其来创建包含所有可用的软件包的名称的文件,并命名为 packagelist:
apt-cache dumpavail | grep -oP "(?<=Package: ).*" >> packagelist而在已获取可用软件包列表的情况下,本文借助 apt-get 完成软件包下载的任务。通过 apt-get source 指令,可以从软件包存储库中下载相应软件包的源代码,该目录的名称以软件包的名称和版本号进行命名,基本形式为 <package_name>-<package_version>。
由于在软件包名称和软件包版本号中均可能存在分隔符 “-”(如 aewm++-goodies-1.0、aephea-12-248 等),仅采用 “-” 作为分隔符进行匹配会带来包名解析异常的问题,注意到版本号部分一定以数字作为起始字符,本文采用如下懒惰匹配进行解析:
解析 Java Maven 依赖声明文件
POM(Project Object Model,项目对象模型)是 Maven 工程的基本工作单元,以 XML 文件的形式呈现,包含了项目的基本信息。在 Maven 中,基本坐标 (Coordinates) 是指用于唯一标识一个项目的三个主要元素:groupId、artifactId 和 version。通过使用这个基本坐标,Maven 可以准确定位和管理项目的依赖关系,并下载正确的库文件。
- groupId: 组织标识。实际对应Java的包的结构,如 org.springframework.boot 等;
- artifactId: 项目标识。通常是工程的名称,如 tomcat、commons 等;
- version: 版本号。用以区分不同的版本,如2.7.3等。
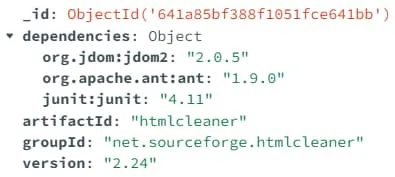
xml.etree.ElementTree 是 Python 标准库中的一个模块,它提供了一种简单而高效的方法来解析和操作 XML 数据。本文借助该模块首先对项目的基本坐标进行解析,并提取 dependencies 标签中的所有内容,对于其中的各个 dependency 项逐个提取依赖的基本坐标,从而完成对于 Java Maven 依赖声明文件的解析。以软件包 libhtmlcleaner-java 为例,解析结果如下图所示:
解析 JavaScript NPM 依赖声明文件
NPM (Node Package Manager) 是一个用于管理和共享 JavaScript 代码的包管理器。在 Node.js 项目的根目录下,会存在 package.json 文件,该文件用于描述项目的元数据和配置信息。对于一个典型的 package.json 文件而言,我们关注其中以下部分的信息和配置项:
- name:指明项目的名称;
- version:指明项目的版本;
- dependencies:列出了项目的运行时依赖包及其版本号。这些依赖项在项目的运行过程中是必需的;
- devDependencies:列出了项目的开发时依赖包及其版本号。这些依赖项在项目的开发和构建过程中是必需的,但在运行时不是必需的。
为了实现依赖项的解析,本质上就是要从 package.json 文件中查找并存储所需的信息,主要思路有如下三种:
- 在当前项目内,借助一些 NPM 命令行工具本身提供的命令查看依赖,如 npm list,其会遍历 package.json 文件中声明的依赖关系,并呈现为当前项目中安装的所有 NPM 软件包及其依赖项的树状结构;
- 借助一些第三方工具完成解析,如 Node.js 第三方库 read-package-json,它可用于 package.json 文件的读取和解析,使用 readJson 函数传入文件路径,对于回调函数的解析结果对象进行读取,便可存储所需的 dependencies 等字段的值;
- 通过 Python 内置的 JSON 模块直接处理。
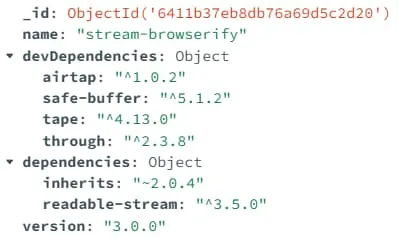
这些方法殊途同归,我们采用 read-package-json 实现解析任务。以软件包 node-stream-browserify 为例,解析结果如下图所示:
解析 Python Pip 依赖声明文件
在 Python 的常用的包管理系统 pip 中,为了在其它生产环境内可以快速并准确地安装相同的依赖,通常采用依赖声明文件来明确列出项目所需要的所有依赖包。而 Python 项目常用的依赖声明文件包括 setup.py 和 requirements.txt。
解析 setup.py 文件中的依赖项
setup.py 是用于构建和发布 Python 包的标准工具,它是一种较传统的依赖声明方式。该文件通常使用 setuptools 库,以定义项目的元数据和依赖关系。在该文件中,往往需要调用 setup() 函数,其中有多种类型的参数,而依赖项参数 (Dependency Parameters) 则主要分为如下几种:
- install_requires:最核心的依赖项,用于指定项目正确运行所需的最少依赖项;
- extras_require:可选的依赖项,主要为一些特殊的、额外的功能所需的依赖项;
- python_requires:用于指定运行时需要的 Python 版本,以避免代码不兼容等问题;
- tests_require:在运行测试时所需的依赖;
- setup_requires:在执行 setup.py 时所需的依赖。
根据各个参数的作用的不同,在解析依赖项时,仅需关注 install_requires 即可。与此前对 Maven、NPM 的依赖声明文件的解析所不同的是,pom.xml 和 package.json 均以结构化的形式存储和表示项目的元数据,而 setup.py 作为脚本文件,在不运行文件的情况下,则难以直接解析其中声明的依赖项。
distutils.core 模块中的 run_setup() 函数提供了一种可行的思路,调用该函数会加载并执行 setup.py 文件,并便捷的获取所需的依赖项列表。采用这个方法可以很好的实现对单个项目的依赖项提取,然而,由于需要安装处理的 Python 包数量较多,各个 Python 包间的依赖关系错综复杂,在进行大规模解析的过程中遇到了一定的阻碍。
解析 requirements.txt 文件中的依赖项
requirements.txt 是 Python 项目中最常用的依赖声明文件,它会精确地列出所有的依赖包及其版本号,文件中的每一行包含一个依赖项及其版本要求。requirements.txt 的广泛应用能够方便项目的部署和共享,确保在不同的环境中安装和运行项目时所需的依赖项能够被正确的安装。
其使用特定的语法来表示依赖关系,通常是以包名和版本号的形式列出,然而也存在一些如通过 URL 或文件路径来表示依赖项等特殊情形,因此手动解析 requirements.txt 文件具有一定的复杂性。为了实现 requirements.txt 依赖项的解析,主要有如下两种方法:
- 使用 pip 的内部函数 parse_requirements。其以 requirements.txt 文件作为输入,并返回解析后的依赖项列表。每个依赖项都表示为 InstallRequirement 对象,可以通过访问其属性来获取相关信息,如软件包名称、版本要求等。
- 借助 Python 模块 Requirements Parser。它提供了一个方便的接口以解析 requirements.txt 文件,通过 parse 函数读取文件对象,可以访问返回的迭代器以存储每个依赖项的各个属性(如名称、版本号、URL、编辑模式等)。
采用 PyCD 解析 Python 项目的依赖信息
经过分别解析软件包中包含的 setup.py 和 requirements.txt 文件,本文对 Ubuntu 所有软件包的 Pip 应用层依赖进行了初步的检测。更进一步的,Cao 等人将 Python 项目中依赖声明文件存在的问题分为三类:依赖缺失、依赖冗余以及版本约束不一致,并实现了可准确地从配置文件中提取依赖项信息的工具 PyCD (Python Cross-project Dependency)。
考虑到依赖声明文件编写过程中存在的问题会对构建依赖关系造成干扰,且目标解析项目中约有 22.1% (271/1226) 同时包含 setup.py 和 requirements.txt 文件,难以直接确定依赖项的选定标准,因此仅通过单文件的解析结果来构建应用层依赖关系并不合适。
本文借助 PyCD,对于目标项目完成依赖项的解析。以软件包 abinit_9.6.2-1build1 为例,解析结果如下表所示。通过表中的 filepath 一栏,可以看出该项目的应用层依赖分别定义于三个不同的文件中,充分展现了单文件解析依赖关系的不可行性。
| dep | version | filepath | type |
|---|---|---|---|
| pygments | ==* | ~/abisrc_requirements.txt | * |
| pandas | ==* | ~/abisrc_requirements.txt | * |
| graphviz | ==* | ~/abisrc_requirements.txt | * |
| panel | ==* | ~/abisrc_requirements.txt | * |
| mkdocs-material | ==7.0.6 | ~/requirements.txt | * |
| pytest | ==* | ~/requirements.txt | * |
| pyyaml | ==* | ~/requirements.txt | * |
| pymdown-extensions | ==8.2 | ~/requirements.txt | * |
| mkdocs | ==1.1.2 | ~/requirements.txt | * |
| pygments | ==* | ~/requirements.txt | * |
| python-markdown-math | ==* | ~/requirements.txt | * |
| html2text | ==* | ~/requirements.txt | * |
| pybtex | ==* | ~/requirements.txt | * |
| numpy | ≥1.8 | ~/scripts/post_processing/ | |
| ElectronPhononCoupling/setup.py | original | ||
| mpi4py | ≥2.0 | ~/scripts/post_processing/ | |
| ElectronPhononCoupling/setup.py | original | ||
| netCDF4 | ≥1.2 | ~/scripts/post_processing/ | |
| ElectronPhononCoupling/setup.py | original |
构建应用层软件包依赖图
在实现应用层包管理器的依赖声明文件解析器后,本文完成 Ubuntu 22.04 应用层软件包的依赖项的提取。进一步的,本文对所有操作系统软件包中引入了这些包管理器软件包的部分构建依赖关系图,以直观呈现应用层软件包间的供应链。其中,Maven、NPM、Pip 软件包应用层依赖图如下图所示:

根据 package.json 文件的规范,dependencies 字段中对于各个依赖项的声明的版本号部分存在多种表示形式,如本地文件路径、Git 仓库地址或是任一可下载的压缩包 URL 等。版本号的形式的多样性会为构建依赖关系带来不必要的麻烦,本文对其进行简化,在构建包含 NPM 软件包的依赖图中仅考虑依赖项的名称。
在解析完毕依赖关系后,我们可以建立完整的操作系统软件供应链并进行可视化,以便进行进一步的分析,详见下篇博文。